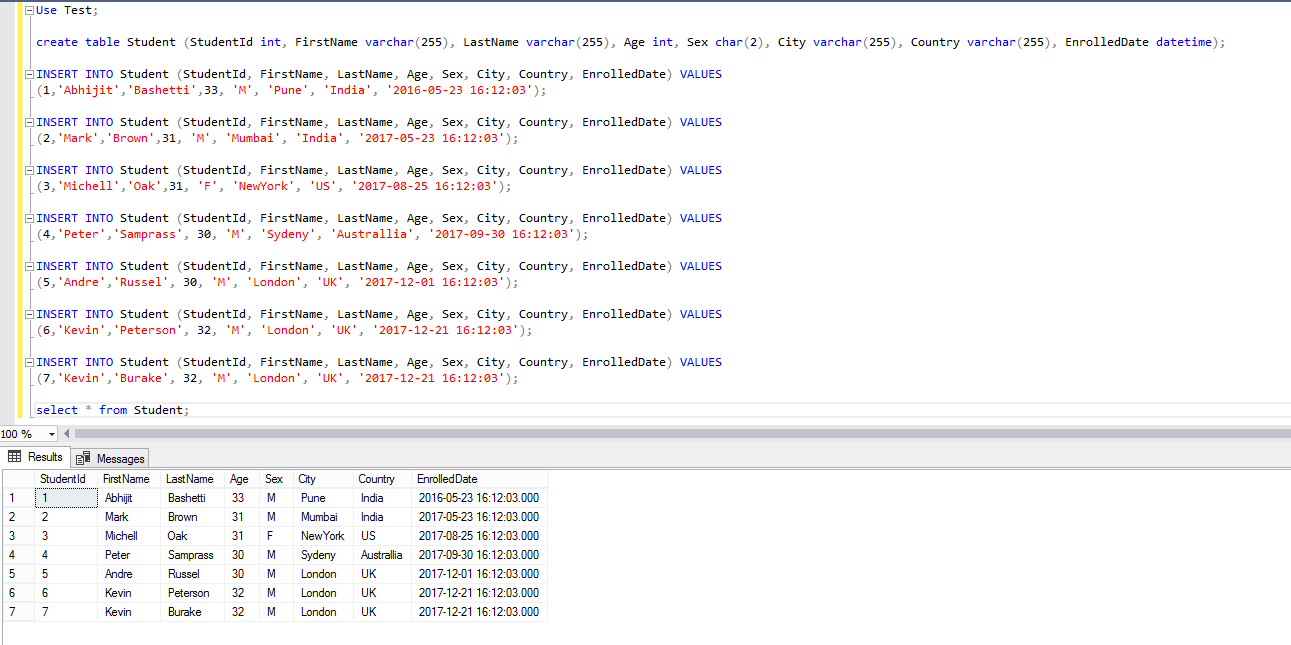
In order to avoid the duplication issues at elasticsearch you may need to add the unique id for the documents at elasticsearch.
Modify the logstashMSSQL_Test.conf by adding the "document_id" => "%{studentid}" in the output like below.
output {
stdout { codec => json_lines }
elasticsearch {
"hosts" => "localhost:9200"
"index" => "test-migrate"
"document_type" => "data"
"document_id" => "%{studentid}"
}
Schedule the same migration if the data is continuosly been updateded on the MSSQL Sever side
This will be running after every one minute
Add the below part in order to incrementing update
schedule => "* * * * *"
statement => "SELECT * FROM Student where studentid > :sql_last_value"
use_column_value => true
tracking_column => studentid
input {
jdbc {
jdbc_connection_string => "jdbc:sqlserver://localhost:1433;databaseName=test"
# The user we wish to execute our statement as
jdbc_user => "sa"
jdbc_password => "sasa"
# The path to our downloaded jdbc driver
jdbc_driver_library => "C:\Users\abhijitb\.m2\repository\com\microsoft\sqlserver\mssql-jdbc\6.2.2.jre8\mssql-jdbc-6.2.2.jre8.jar"
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
# our query
#clean_run => true
schedule => "* * * * *"
statement => "SELECT * FROM Student where studentid > :sql_last_value"
use_column_value => true
tracking_column => "studentid"
}
}
output {
#stdout { codec => json_lines }
elasticsearch {
"hosts" => "localhost:9200"
"index" => "student"
"document_type" => "data"
"document_id" => "%{studentid}"
}
}
Add the data to Table Student one by one.
INSERT INTO Student (StudentId, FirstName, LastName, Age, Sex, City, Country, EnrolledDate) VALUES
(8,'David','Bruce', 32, 'M', 'Paris', 'FRANCE', GETDATE());
INSERT INTO Student (StudentId, FirstName, LastName, Age, Sex, City, Country, EnrolledDate) VALUES
(9,'Steve','Warne', 30, 'M', 'Paris', 'FRANCE', GETDATE()-200);
INSERT INTO Student (StudentId, FirstName, LastName, Age, Sex, City, Country, EnrolledDate) VALUES
(10,'Ajit','Patil', 32, 'M', 'Pune', 'India', GETDATE()-100);
INSERT INTO Student (StudentId, FirstName, LastName, Age, Sex, City, Country, EnrolledDate) VALUES
(11,'Steve','Scot', 32, 'M', 'Paris', 'FRANCE', GETDATE()-50);
Once you update the file, go the
Go the path C:\logstash-6.5.4\logstash-6.5.4\bin> on the command prompt.
run the below command "logstash -f logstashMSSQL_Test.conf"
C:\logstash-6.5.4\logstash-6.5.4\bin>logstash -f logstashMSSQL_Test.conf

To verify the Data on the ElasticSeach side click the link on the browser.
http://localhost:9200/student/_search?pretty=true

Check the data in descending order. You can verify the when the data is added to elastic search by checking the timestamp of it.
http://localhost:9200/student/_search?q=*&sort=studentid:desc&pretty=true

To check more properties visit https://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html
Modify the logstashMSSQL_Test.conf by adding the "document_id" => "%{studentid}" in the output like below.
output {
stdout { codec => json_lines }
elasticsearch {
"hosts" => "localhost:9200"
"index" => "test-migrate"
"document_type" => "data"
"document_id" => "%{studentid}"
}
Schedule the same migration if the data is continuosly been updateded on the MSSQL Sever side
This will be running after every one minute
Add the below part in order to incrementing update
schedule => "* * * * *"
statement => "SELECT * FROM Student where studentid > :sql_last_value"
use_column_value => true
tracking_column => studentid
input {
jdbc {
jdbc_connection_string => "jdbc:sqlserver://localhost:1433;databaseName=test"
# The user we wish to execute our statement as
jdbc_user => "sa"
jdbc_password => "sasa"
# The path to our downloaded jdbc driver
jdbc_driver_library => "C:\Users\abhijitb\.m2\repository\com\microsoft\sqlserver\mssql-jdbc\6.2.2.jre8\mssql-jdbc-6.2.2.jre8.jar"
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
# our query
#clean_run => true
schedule => "* * * * *"
statement => "SELECT * FROM Student where studentid > :sql_last_value"
use_column_value => true
tracking_column => "studentid"
}
}
output {
#stdout { codec => json_lines }
elasticsearch {
"hosts" => "localhost:9200"
"index" => "student"
"document_type" => "data"
"document_id" => "%{studentid}"
}
}
Add the data to Table Student one by one.
INSERT INTO Student (StudentId, FirstName, LastName, Age, Sex, City, Country, EnrolledDate) VALUES
(8,'David','Bruce', 32, 'M', 'Paris', 'FRANCE', GETDATE());
INSERT INTO Student (StudentId, FirstName, LastName, Age, Sex, City, Country, EnrolledDate) VALUES
(9,'Steve','Warne', 30, 'M', 'Paris', 'FRANCE', GETDATE()-200);
INSERT INTO Student (StudentId, FirstName, LastName, Age, Sex, City, Country, EnrolledDate) VALUES
(10,'Ajit','Patil', 32, 'M', 'Pune', 'India', GETDATE()-100);
INSERT INTO Student (StudentId, FirstName, LastName, Age, Sex, City, Country, EnrolledDate) VALUES
(11,'Steve','Scot', 32, 'M', 'Paris', 'FRANCE', GETDATE()-50);
Once you update the file, go the
Go the path C:\logstash-6.5.4\logstash-6.5.4\bin> on the command prompt.
run the below command "logstash -f logstashMSSQL_Test.conf"
C:\logstash-6.5.4\logstash-6.5.4\bin>logstash -f logstashMSSQL_Test.conf

To verify the Data on the ElasticSeach side click the link on the browser.
http://localhost:9200/student/_search?pretty=true
Check the data in descending order. You can verify the when the data is added to elastic search by checking the timestamp of it.
http://localhost:9200/student/_search?q=*&sort=studentid:desc&pretty=true
To check more properties visit https://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html