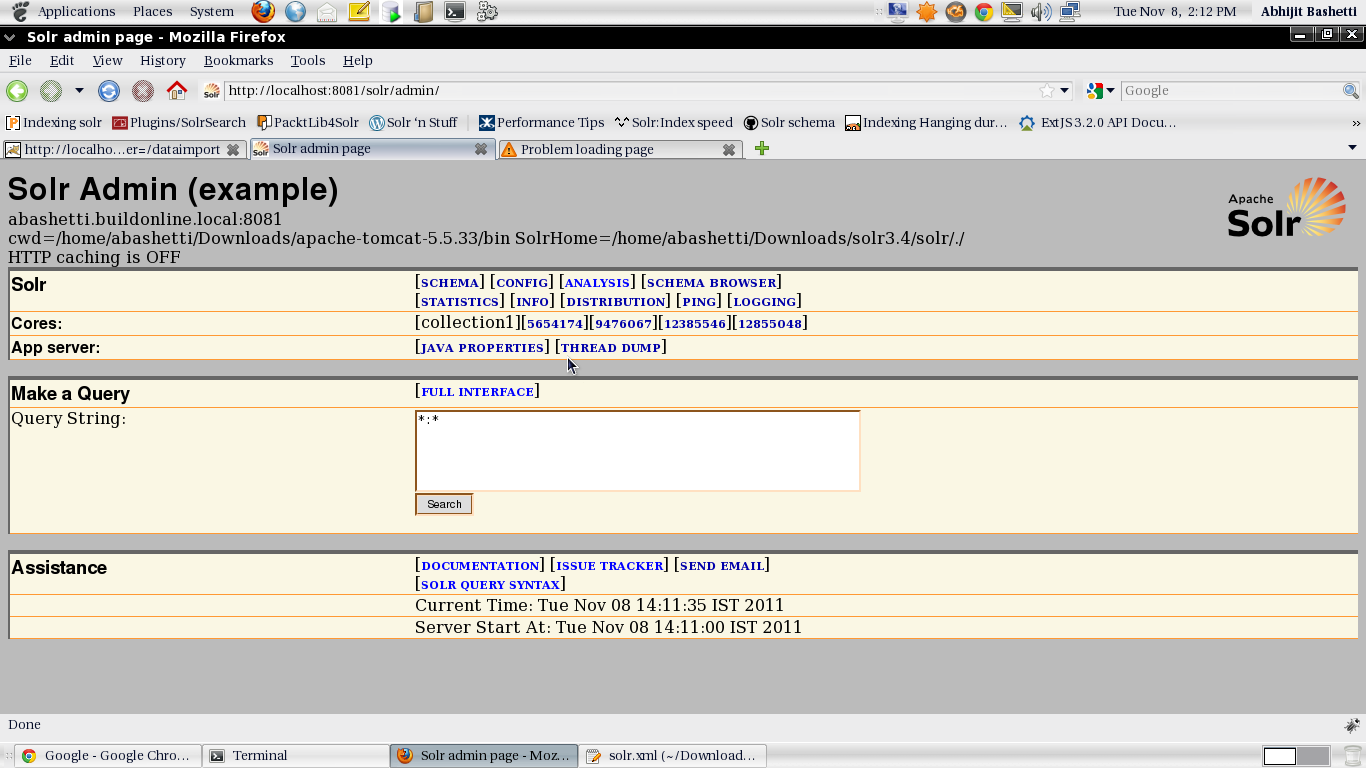
Multiple cores allows you create seperate index files for every single module of your application. Here each core has its own configuration file e.g every core can have its own data-config.xml, solr-config.xml and schema.xml. We can make the seperate index file for each core. You can also administer those cores using http://localhost:8080/solr/ .
Cores are created on the fly by using http://localhost:8080/solr/admin/cores?action=CREATE&name=coreX&instanceDir=path_to_instance_directory&config=config_file_name.xml&schema=schem_file_name.xml&dataDir=data. Here the Create is action name for creating core, name is the unique name for the core, instanceDir is the path solr home, config is the path of the solrConfig.xml, schema is the path of schema.xml and finally the dataDir is the path where one wants to store the index files.
In my case it was : http://localhost:8080/solr/admin/cores?action=CREATE&name=9476067&instanceDir=/home/abashetti/Downloads/abhijit/solr/&config=/home/abashetti/Downloads/abhijit/solr/conf/solrconfig.xml&schema=/home/abashetti/Downloads/abhijit/solr/conf/schema.xml&dataDir=/home/abashetti/Downloads/abhijit/solr/9476067/document/data
This will create an entry in the solr.xml file.
The default solr.xml file will look like :
The defaultCoreName must be mentioned the xml file.
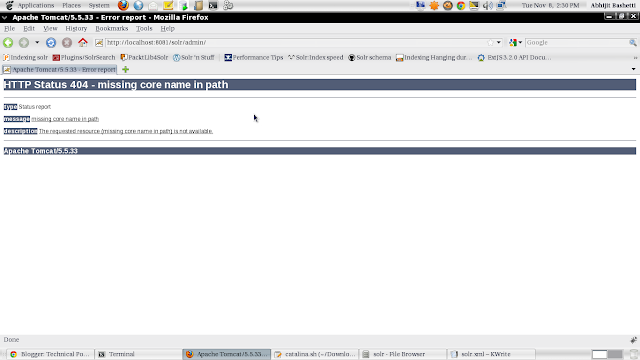
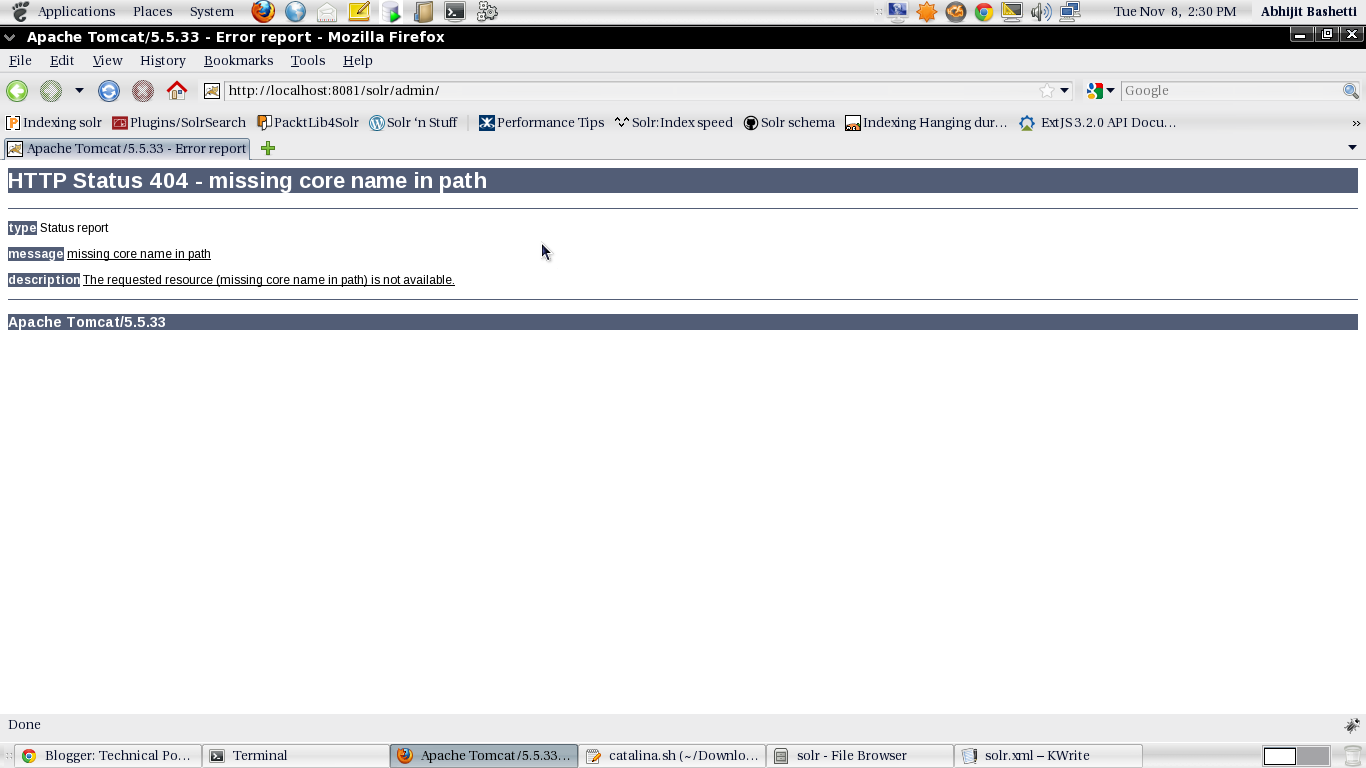
If the default core name is missing you will get the error on the browser as :
<?xml version="1.0" encoding="UTF-8" ?>
<solr persistent="false">
<cores adminPath="/admin/cores" defaultCoreName="collection1">
<core name="collection1" instanceDir="." />
To create core on fly one need to modify the solr.xml , the attribute persistent ="true" is the change for it.
<?xml version="1.0" encoding="UTF-8" ?>
<solr persistent="true">
<cores adminPath="/admin/cores" defaultCoreName="collection1">
<core name="collection1" instanceDir="." />
<core name="9476067" instanceDir="./" config="/home/abashetti/Downloads/abhijit/solr/conf/solrconfig.xml"
schema=/home/abashetti/Downloads/abhijit/solr/conf/schema.xml
dataDir="/home/abashetti/Downloads/abhijit/solr/9476067/data"
/>
<core name="12385546" instanceDir="./"
config="/home/abashetti/Downloads/abhijit/solr/conf/solrconfig.xml"
schema=/home/abashetti/Downloads/abhijit/solr/conf/schema.xml
dataDir="/home/abashetti/Downloads/abhijit/solr/12385546/data"/>
</cores>
The core can be reloaded, removed on the fly. To remove/unload the core on fly use the url
http://localhost:8080/solr/admin/cores?action=UNLOAD&core=9476067&deleteIndex=true
Cores are created on the fly by using http://localhost:8080/solr/admin/cores?action=CREATE&name=coreX&instanceDir=path_to_instance_directory&config=config_file_name.xml&schema=schem_file_name.xml&dataDir=data. Here the Create is action name for creating core, name is the unique name for the core, instanceDir is the path solr home, config is the path of the solrConfig.xml, schema is the path of schema.xml and finally the dataDir is the path where one wants to store the index files.
In my case it was : http://localhost:8080/solr/admin/cores?action=CREATE&name=9476067&instanceDir=/home/abashetti/Downloads/abhijit/solr/&config=/home/abashetti/Downloads/abhijit/solr/conf/solrconfig.xml&schema=/home/abashetti/Downloads/abhijit/solr/conf/schema.xml&dataDir=/home/abashetti/Downloads/abhijit/solr/9476067/document/data
This will create an entry in the solr.xml file.
The default solr.xml file will look like :
The defaultCoreName must be mentioned the xml file.
If the default core name is missing you will get the error on the browser as :
<?xml version="1.0" encoding="UTF-8" ?>
<solr persistent="false">
<cores adminPath="/admin/cores" defaultCoreName="collection1">
<core name="collection1" instanceDir="." />
</cores>
</solr>
<?xml version="1.0" encoding="UTF-8" ?>
<solr persistent="true">
<cores adminPath="/admin/cores" defaultCoreName="collection1">
<core name="collection1" instanceDir="." />
<core name="9476067" instanceDir="./" config="/home/abashetti/Downloads/abhijit/solr/conf/solrconfig.xml"
schema=/home/abashetti/Downloads/abhijit/solr/conf/schema.xml
dataDir="/home/abashetti/Downloads/abhijit/solr/9476067/data"
/>
<core name="12385546" instanceDir="./"
config="/home/abashetti/Downloads/abhijit/solr/conf/solrconfig.xml"
schema=/home/abashetti/Downloads/abhijit/solr/conf/schema.xml
dataDir="/home/abashetti/Downloads/abhijit/solr/12385546/data"/>
</cores>
</solr>
http://localhost:8080/solr/admin/cores?action=UNLOAD&core=9476067&deleteIndex=true
The above url will remove the entry of core from solr.xml and remove the index files from the dataDir.

Here the UNLOAD is the action for removing the core and core attribute asks you for the core name and if you want to delete the index files then set deleteIndex value is true. If deleteIndex is false then solr will remove only the core entry from the solr.xml.
The url to check all the core is http://localhost:8080/solr/admin/