WildCard
Search with Solr.
Considering
a scenario where one wants to have the wildcard search. In the same
case Solr has provided a N-gram filter. Lets see how to use the same
for various requirements. Solr has provided many tokenizers and filters. Combine these tokenizers and filters to get the desired
result. The wildcard
field
can be used for autocomplete feature.
- To have the forward wildcard search create the field type in solr schema.xml as :
<fieldType
name="wildCardType"
class="solr.TextField" sortMissingLast="true"
omitNorms="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory"
minGramSize="3" maxGramSize="50"
side="front"/>
</analyzer>
<analyzer type="query">
<tokenizer
class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
The
text to be indexed is “Enterprise”
KeywordTokenizerFactory
output is :
Enterprise
LowerCaseFilterFactory output is :
enterprise
NgramFilterFactory output is :
ent ente enter enterp enterpr enterpri enterpris enterprise
The final output for indexing is : ent ente enter enterp enterpr enterpri enterpris enterprise
The final output for indexing is : ent ente enter enterp enterpr enterpri enterpris enterprise
In
this case if you enter “enter*” or “enterpr*” you will get the
result.
- To have the backward wildcard search create the field type in solr as :only one change for the backward wildcard search is the change the side to back.<filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="50" side="back"/>
- To use the wildcard search from both side create the field type in solr as :In this case add Ngram filter twice.
<filter
class="solr.EdgeNGramFilterFactory" minGramSize="3"
maxGramSize="50" side="front"/>
<filter
class="solr.EdgeNGramFilterFactory" minGramSize="3"
maxGramSize="50" side="back"/>
The
text to be indexed is “Enterprise”
KeywordTokenizerFactory
output is :
Enterprise
LowerCaseFilterFactory output is :
enterprise
NgramFilterFactory output is :
ent nte ente ter nter enter erp terp nterp enterp rpr erpr terpr
nterpr enterpr pri rpri erpri terpri nterpri enterpri ris pris
rpris erpris terpris nterpris enterpris ise rise prise rprise
erprise terprise nterprise enterprise
The benefit of the 3rd way is when search should be for any of the character from the specified word. In my case it was the title of the document to be searched in similar way. So I indexed the title using two n-gram , one form front and other from back as shown above. But I suggest not use use this for long text like documents content, as it will take hamper the indexing performance. This field type is useful when you want to search for any of characters from that word and case like autocomplete.
You can create a customised field
type using the tokenizers and filters provided by solr.
Create you own field type and analyse
the same using the analysis admin page of solr.
Link to the analysis page is
http://localhost:8080/solr/admin/analysis.jsp. The analysis.jsp can be used to verify the search match. It helps you in investigating what went wrong with the indexing and query output.
The analysis page looks like this for
the above wildCardType
when
you
use the Ngram filter twice from the front and back side:

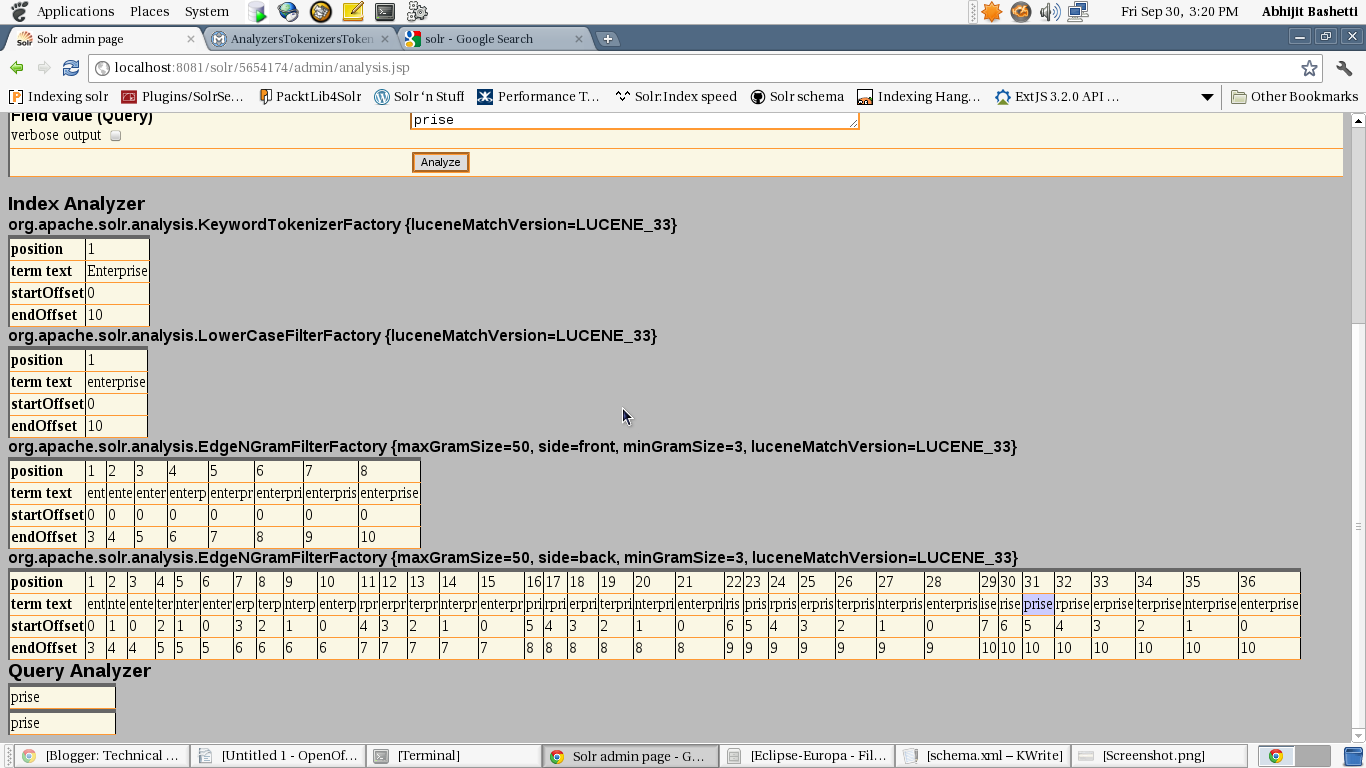
If you want matching prefix substrings indexing the word from front side.
Use the below fieldType :
<fieldType name="wildCardType" class="solr.TextField" sortMissingLast="true" omitNorms="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="50" side="front"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Use the below fieldType :
<fieldType name="wildCardType" class="solr.TextField" sortMissingLast="true" omitNorms="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="50" side="front"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>

