Long back I had written blogs on solr setup and how I used it in my application.
Meanwhile I am getting questions/quries from the readers on the same.
And these readers make you to work on it...revisit the technologies or stuffs your had worked...
The queries are like I am searching "Solr Blog" as text but getting the results of "Solr" as well
"Solr indexing" or my blah blah search text is not getting the correct result.
After going through all these quries I realised that where it is going wrong.
Or rather how my blogs are not helping them to resolve their issues...
So I decided to write another one which may ease their job or guide them working on solr and
will brush up my knowledge on the same subject :)
Lets go with the real example, which made me to pen down this blog ...
A reader asked me a question :
"If he search for "Abhijit & his blogs", It should show the exact match as "Abhijit & his blogs" and not matches like "Abhijit" or
or "Abhijit Songs"... ".
On this what all questions comes to your mind...? What would be wrong here ...?
any idea...?
There is simple theory ...what you index, will be available for search... :)
In short you are using a wrong analyzer for indexing and quering...
Find out which is the fieldType been used for indexing and querying....
Is it the default provided by Solr or you have written your own custom field type(created by using the
available tokenizers and filtes)..
For the above example turn off the stemming ...
The solutions for the problem would be...
<types>
<fieldType name="text_no_stem" class="solr.TextField" omitNorms="false">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StandardFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</types>
<fields>
<dynamicField name="*_nostem" type="text_no_stem" indexed="true" stored="true"/>
</fields>
Or Use solr string field whcih will do an exact value search e.g
<fieldType class="solr.StrField" name="string" omitNorms="true" sortMissingLast="true" />
Now coming to the point what I realised ..?
That is we need to know more on the role tokenizers and filtes in the analyzers.
Which all types of tokenizers and filtes are available...how to make use of it and when to use it..
How to test the same...?
Here is the brief about the three important things
1. Analyzer : They pre-process the test at the time of indexing and quering(or search). Ans yes make sure you are using same analyzers that for both index and query.
For example, if an indexing analyzer lowercases words, then the query analyzer should do the same to enable finding the indexed words.
2. Tokenizers : It splits/seperates stream of characters into a series of tokens or small chunks/words. There can be only one Tokenizer in each Analyzer.
There are different tokenizer available to use. For example..
KeywordTokenizerFactory
LetterTokenizerFactory
WhitespaceTokenizerFactory
StandardTokenizerFactory
LowerCaseTokenizerFactory
3. Filters : This takes a granular level of tokes. doing many changes to it before indexing it.
There are different filters available to use..
LowerCaseFilterFactory
ClassicFilterFactory
StopFilterFactory
EdgeNGramFilterFactory
and many more are available.
You should be very precise about how and what is the way you want your search should work.
Then its very easy to decide the fieldType ...rather very easy to create your own type and use it.
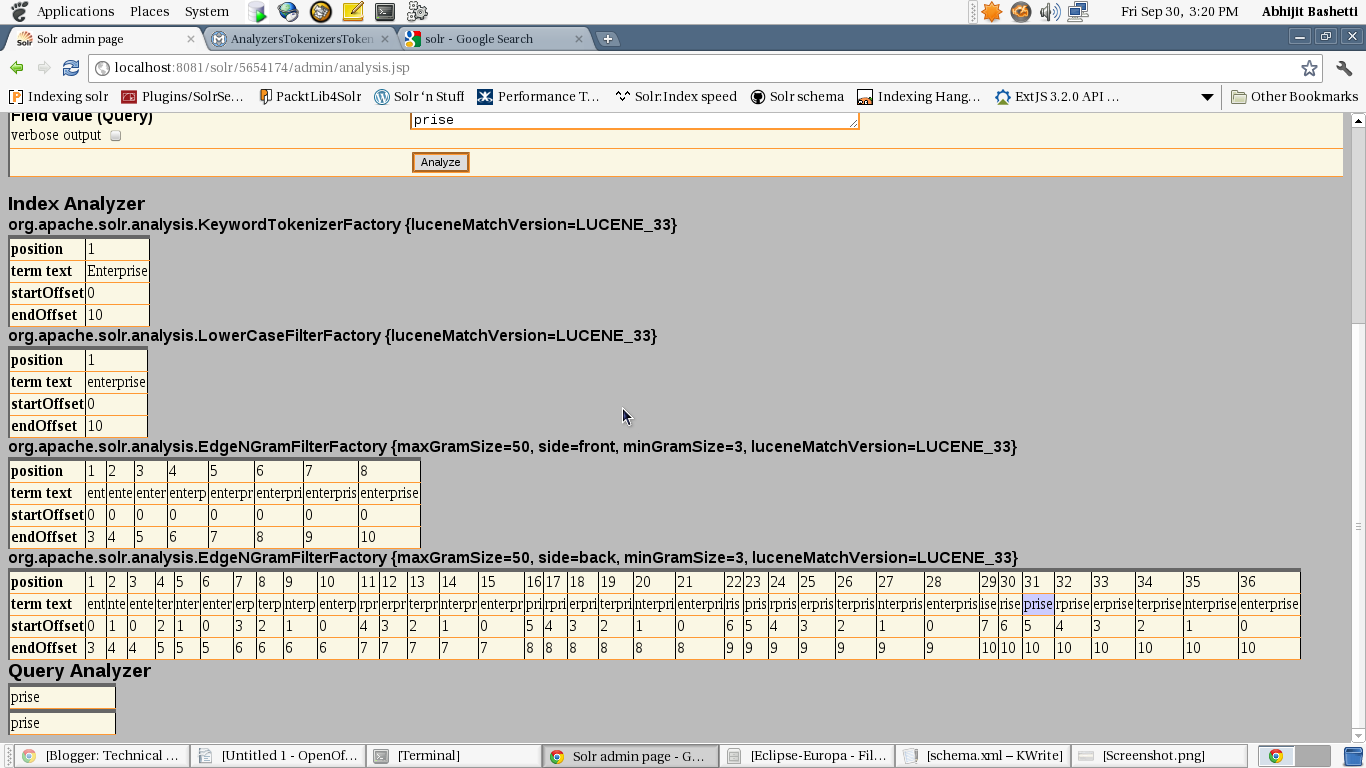
While doing any sort of analysis do use the tool given by solr i.e analysis.jsp.
It will help you a lot for resolving your problems...
If you want to read more about the solr's tokenizer's and filter's refere the solr Wiki which has a lot info
https://wiki.apache.org/solr/
Please feel free to put on your view on it...
Meanwhile I am getting questions/quries from the readers on the same.
And these readers make you to work on it...revisit the technologies or stuffs your had worked...
The queries are like I am searching "Solr Blog" as text but getting the results of "Solr" as well
"Solr indexing" or my blah blah search text is not getting the correct result.
After going through all these quries I realised that where it is going wrong.
Or rather how my blogs are not helping them to resolve their issues...
So I decided to write another one which may ease their job or guide them working on solr and
will brush up my knowledge on the same subject :)
Lets go with the real example, which made me to pen down this blog ...
A reader asked me a question :
"If he search for "Abhijit & his blogs", It should show the exact match as "Abhijit & his blogs" and not matches like "Abhijit" or
or "Abhijit Songs"... ".
On this what all questions comes to your mind...? What would be wrong here ...?
any idea...?
There is simple theory ...what you index, will be available for search... :)
In short you are using a wrong analyzer for indexing and quering...
Find out which is the fieldType been used for indexing and querying....
Is it the default provided by Solr or you have written your own custom field type(created by using the
available tokenizers and filtes)..
For the above example turn off the stemming ...
The solutions for the problem would be...
<types>
<fieldType name="text_no_stem" class="solr.TextField" omitNorms="false">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StandardFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</types>
<fields>
<dynamicField name="*_nostem" type="text_no_stem" indexed="true" stored="true"/>
</fields>
Or Use solr string field whcih will do an exact value search e.g
<fieldType class="solr.StrField" name="string" omitNorms="true" sortMissingLast="true" />
Now coming to the point what I realised ..?
That is we need to know more on the role tokenizers and filtes in the analyzers.
Which all types of tokenizers and filtes are available...how to make use of it and when to use it..
How to test the same...?
Here is the brief about the three important things
1. Analyzer : They pre-process the test at the time of indexing and quering(or search). Ans yes make sure you are using same analyzers that for both index and query.
For example, if an indexing analyzer lowercases words, then the query analyzer should do the same to enable finding the indexed words.
2. Tokenizers : It splits/seperates stream of characters into a series of tokens or small chunks/words. There can be only one Tokenizer in each Analyzer.
There are different tokenizer available to use. For example..
KeywordTokenizerFactory
LetterTokenizerFactory
WhitespaceTokenizerFactory
StandardTokenizerFactory
LowerCaseTokenizerFactory
3. Filters : This takes a granular level of tokes. doing many changes to it before indexing it.
There are different filters available to use..
LowerCaseFilterFactory
ClassicFilterFactory
StopFilterFactory
EdgeNGramFilterFactory
and many more are available.
You should be very precise about how and what is the way you want your search should work.
Then its very easy to decide the fieldType ...rather very easy to create your own type and use it.
While doing any sort of analysis do use the tool given by solr i.e analysis.jsp.
It will help you a lot for resolving your problems...
If you want to read more about the solr's tokenizer's and filter's refere the solr Wiki which has a lot info
https://wiki.apache.org/solr/
Please feel free to put on your view on it...