WildCard
Search with Solr.
Considering
a scenario where one wants to have the wildcard search. In the same
case Solr has provided a N-gram filter. Lets see how to use the same
for various requirements. Solr has provided many tokenizers and filters. Combine these tokenizers and filters to get the desired
result. The wildcard
field
can be used for autocomplete feature.
- To have the forward wildcard search create the field type in solr schema.xml as :
<fieldType
name="wildCardType"
class="solr.TextField" sortMissingLast="true"
omitNorms="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory"
minGramSize="3" maxGramSize="50"
side="front"/>
</analyzer>
<analyzer type="query">
<tokenizer
class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
The
text to be indexed is “Enterprise”
KeywordTokenizerFactory
output is :
Enterprise
LowerCaseFilterFactory output is :
enterprise
NgramFilterFactory output is :
ent ente enter enterp enterpr enterpri enterpris enterprise
The final output for indexing is : ent ente enter enterp enterpr enterpri enterpris enterprise
The final output for indexing is : ent ente enter enterp enterpr enterpri enterpris enterprise
In
this case if you enter “enter*” or “enterpr*” you will get the
result.
- To have the backward wildcard search create the field type in solr as :only one change for the backward wildcard search is the change the side to back.<filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="50" side="back"/>
- To use the wildcard search from both side create the field type in solr as :In this case add Ngram filter twice.
<filter
class="solr.EdgeNGramFilterFactory" minGramSize="3"
maxGramSize="50" side="front"/>
<filter
class="solr.EdgeNGramFilterFactory" minGramSize="3"
maxGramSize="50" side="back"/>
The
text to be indexed is “Enterprise”
KeywordTokenizerFactory
output is :
Enterprise
LowerCaseFilterFactory output is :
enterprise
NgramFilterFactory output is :
ent nte ente ter nter enter erp terp nterp enterp rpr erpr terpr
nterpr enterpr pri rpri erpri terpri nterpri enterpri ris pris
rpris erpris terpris nterpris enterpris ise rise prise rprise
erprise terprise nterprise enterprise
The benefit of the 3rd way is when search should be for any of the character from the specified word. In my case it was the title of the document to be searched in similar way. So I indexed the title using two n-gram , one form front and other from back as shown above. But I suggest not use use this for long text like documents content, as it will take hamper the indexing performance. This field type is useful when you want to search for any of characters from that word and case like autocomplete.
You can create a customised field
type using the tokenizers and filters provided by solr.
Create you own field type and analyse
the same using the analysis admin page of solr.
Link to the analysis page is
http://localhost:8080/solr/admin/analysis.jsp. The analysis.jsp can be used to verify the search match. It helps you in investigating what went wrong with the indexing and query output.
The analysis page looks like this for
the above wildCardType
when
you
use the Ngram filter twice from the front and back side:

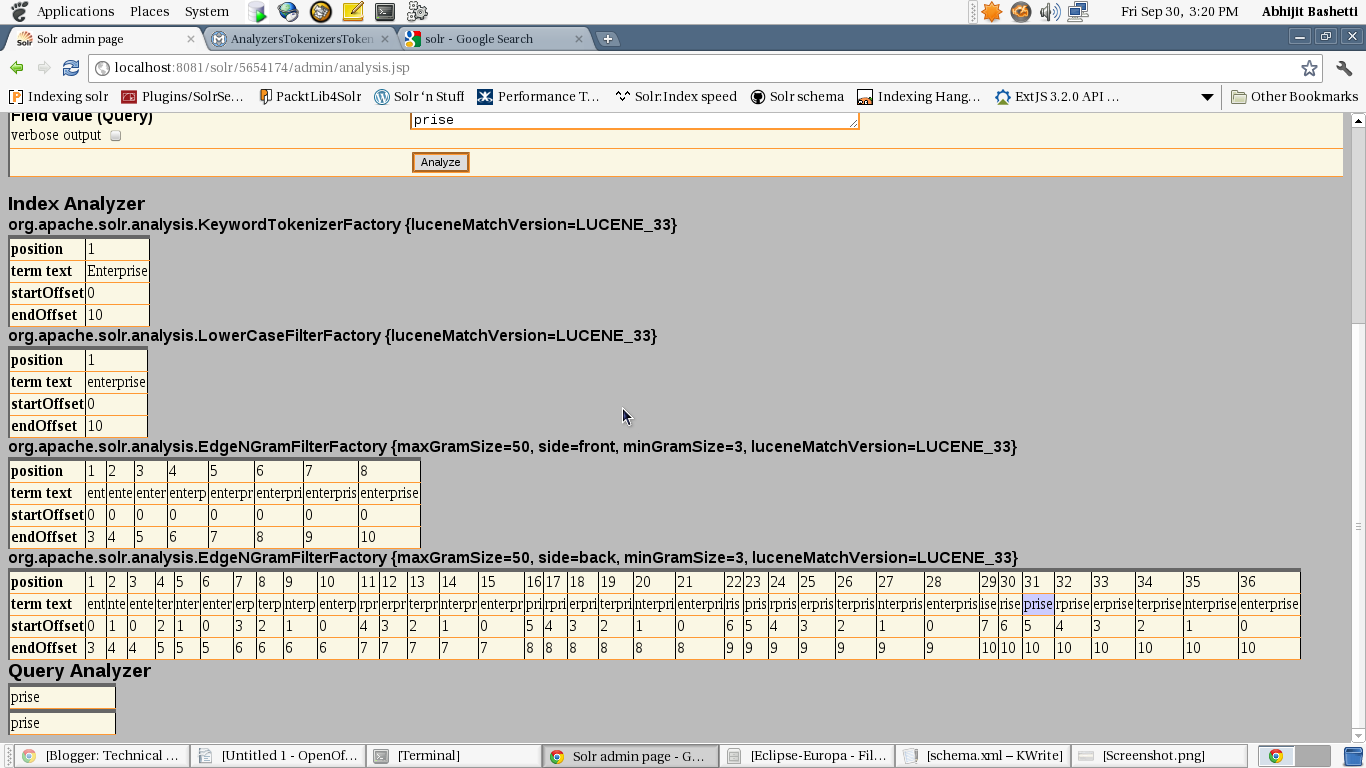
If you want matching prefix substrings indexing the word from front side.
Use the below fieldType :
<fieldType name="wildCardType" class="solr.TextField" sortMissingLast="true" omitNorms="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="50" side="front"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Use the below fieldType :
<fieldType name="wildCardType" class="solr.TextField" sortMissingLast="true" omitNorms="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="50" side="front"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>


Hi Abhijit, Can you tell whether we can use both the following two filter for the same field? Basically i want the same search result for "men text" and "text men". Can you please explain how do we do that?
ReplyDeleteNo sir... applying above filter will create the indexes as..
ReplyDeleteme en men n en men t n t en t men t te te n te en te men te ex tex tex n tex en tex men tex xt ext text text n text en text men text
This filter is used for wild card as in your are searching for 'tex*'
then it will fetch the result as we have the index of it.
But i think you need not have use ngram in this your case because
if you use only WhitespaceTokenizerFactory in your case it has to work...
as in the field type would be ...
Applying this Ngram filter returns same results for "men text" and "text men" search text.
ReplyDeleteI have one more problem here.. if i search "men text" returns records based on OR operation..How i do to get AND operation for the text "men text"..
For example there are 10 results for "men" and 10 results for "text" but the text "men" and "text" both available only on 5 records so when i search "men text" i should apply AND and should get only 5 records.. I can achieve this by searching "men AND text" directly on solr console.Is there a way we can add "AND" if we see space via solr?
I tried
but it doesn't help.
This comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteHi,
ReplyDeleteYou can modify the parameter in schema.xml as
change the solrQueryParser's defaultOperator to "AND" as it's "OR"
change it to "AND" .
But I suggest don't go for it rather add the ""(double quotes) for that word like "men text" and send the query to solr. It will interpret the same and reply with the expected result.
Hi,
ReplyDeleteif i want to return results that only start with a, or am. or amaz. so for example i write q=a(assuming i m using dismax) so it should return all the results that start with a. or if q=am it should return all the results that start with am. rather it gives me all the result even if i have 'am' in the middle of the word and also if i have 'kindle amazon' it returns me this as well. where as i only want the one that start with am so if it was 'amazon kindle' then it should return me this document. how can i modify the code u mentioned to do my required search.
Thanks.
Use only this filter
DeleteAs you want matching prefix substrings indexing the word from front side.
The text to be indexed is “Enterprise”
NgramFilterFactory output is :
ent ente enter enterp enterpr enterpri enterpris enterprise
if you want it from the first character then change minGramSize="1"
Fiter would be like
The text to be indexed is “Enterprise”
NgramFilterFactory output is :
e en ent ente enter enterp enterpr enterpri enterpris enterprise
You can use only this which should solve your problem.
Thanks Abhijiit for sharing this blog post. EdgeNGramFilterFactory doesn't consider special chars. If i search for "Abhijiit & his blogs", it should not show me "Abhijiit" or "Abhijiit songs" where as its showing. How can make this.
ReplyDeleteHi Amol..
DeleteI am glad to know that its useful to you...
Have you written/customised the fieldType?
Is it possible for you to share the fieldType with me?
It would be easy for me to help you with same..
Hi,
Deletewhats the exact is indexing text and search text for you?
I think in your case you should not use "EdgeNGramFilterFactory" as it seems you dont want micro indexing.
You should have KeywordTokenizerFactory as your tokenizer.
Dear Abhijit,
ReplyDeleteMy requirement is that I want to block wildsearch in my site.
Can you show me the way to do so.
Girish
The StrField type is not analyzed, but indexed/stored verbatim.
DeleteYou can change the fieldType for the field you are searching on.
DeleteIt all depends on how you want to provide the search.
You can use string field type for the same field by which the there wont be any analysis on the same field.
The StrField type is not analyzed, but indexed/stored verbatim.
Change the Tokenizer from StandardTokenizerFactory to KeywordTokenizerFactory.
This comment has been removed by the author.
ReplyDeleteHi,
ReplyDeleteCould you please tell me that how to extend maxGramSize to 20? in Solr 5.2.1